


The 2025 Social Media Image Sizes Guide
By Michaela VoglJan 13
Ready to explore our latest product innovations, designed to help you work smarter and take action faster?
Published September 28th 2020
Phill Agnew interviews Brandwatch’s Chief Data Scientist on the science behind our latest feature.
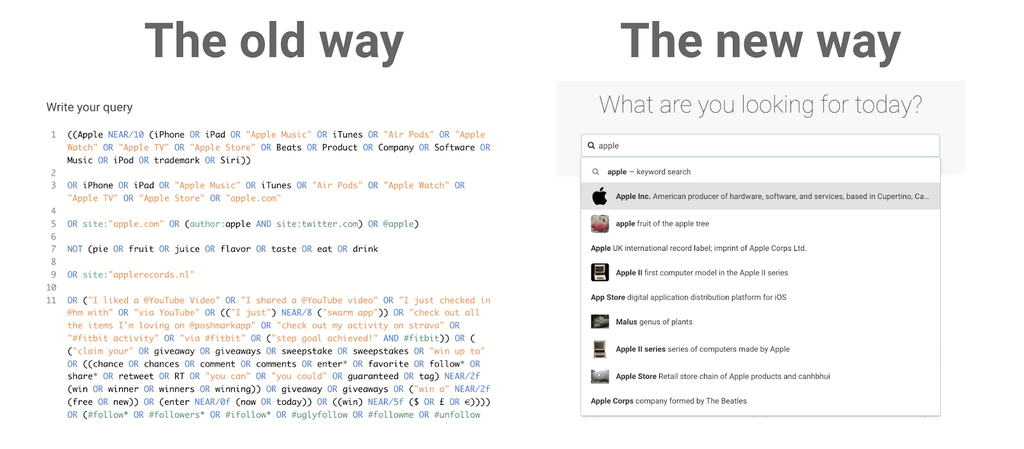
Search, Brandwatch’s latest feature, comes packed with some pretty impressive functionality.
Just like a Google search, users can start to type the entity they want to search for (be it a brand, person, event, etc) and Brandwatch will auto-suggest potential searches.
I was mesmorized when I first tried it. As someone who has spent hundreds of hours writing queries, I could instantly see the huge amount of time this would save me and our clients.
I wanted to find out more about the science behind this great update, so I went to speak to the brains behind it: Brandwatch Chief Data Scientist Aykut Firat. Here’s our discussion:
I am currently the Chief Data Scientist at Brandwatch. I work on NLP and image processing problems using deep learning techniques. Previously, I have worked at startups focusing on intelligent information integration, evolutionary computation, and AI – including one I co-founded with my advisor during my PhD at MIT.
Entity disambiguation extracts entities in text and links them to entities in an unambiguous knowledge base. In our case this knowledge base is Wikipedia.
Essentially, it allows us to make sense of the billions of different conversations happening online and group them into entities. An entity, by the way, can be anything from a brand, person, or event, to even a broad topic like cycling or cybersecurity.
Searching for ambiguous concepts in Brandwatch is difficult. When you search for Apple the company, you may also get unwanted results such as those about apple pie. With entity disambiguation, we only collect the entities you want by reducing or eliminating unwanted results.
From the user perspective, it is as simple as choosing the entity of interest from a list and you get the results.
Technically, on our end it has four major components:
Consider this mention: “Blackberry is about safety, and Apple is about user experience”.
We identify Blackberry and Apple as words of interest that point to entities in Wikipedia. To a human, “safety” and “user experience” give clues about the context of this statement.
Similarly, our patent-pending, AI-based disambiguation engine automatically extracts meaning beyond what appears in the given text. So our AI will recognize that the word “slam dunk” is associated with “Michael Jordan” even if the two terms aren’t mentioned in the same post.
If you are searching for Apple the company, or Apple phone, stored entity and input text features will most likely match and the above text will be returned as a result.
In normal query writing, you often try to add context with extra terms like (Phone OR iPhone OR Mac OR …). This process is very tenuous, incomplete, and sometimes impossible.
For example, a common preposition such as “to” or a possessive “my” can differentiate between the place and car entities as in “I like to drive to Malibu” vs “I like to drive my Malibu”. Most of us struggle to include terms like this when writing a Query, but with Search, the smart AI does it for you.
In many cases, this will be a big improvement on normal query writing as it will likely match more items and match them more accurately when compared to a human-created query.
There are a few things users should be aware of. Search is a brand new innovation from Brandwatch and it’s still being worked on. This means you should expect a number of updates in the near future, but also don’t expect it to be perfect right away. Search works better for some entities than others.
If there are two similar brands referred to with the same word, for example, the system may make more mistakes. When the contexts of competing meanings are more distant the results will be more accurate. It’s also important to note that as of today Search’s entity disambiguation is based on English language.
We’re hard at work providing updates. The big things we’re looking at right now include bringing entity disambiguation to more languages than English.
Thanks to Aykut for taking the time to speak with the blog team.
If you’d like to try Search out for yourself click here to request a demo. If you’re an existing client, access to Search is available now at no extra cost.
Consumer Research gives you access to deep consumer insights from 100 million online sources and over 1.4 trillion posts.
Existing customer?Log in to access your existing Falcon products and data via the login menu on the top right of the page.New customer?You'll find the former Falcon products under 'Social Media Management' if you go to 'Our Suite' in the navigation.
Brandwatch acquired Paladin in March 2022. It's now called Influence, which is part of Brandwatch's Social Media Management solution.Want to access your Paladin account?Use the login menu at the top right corner.