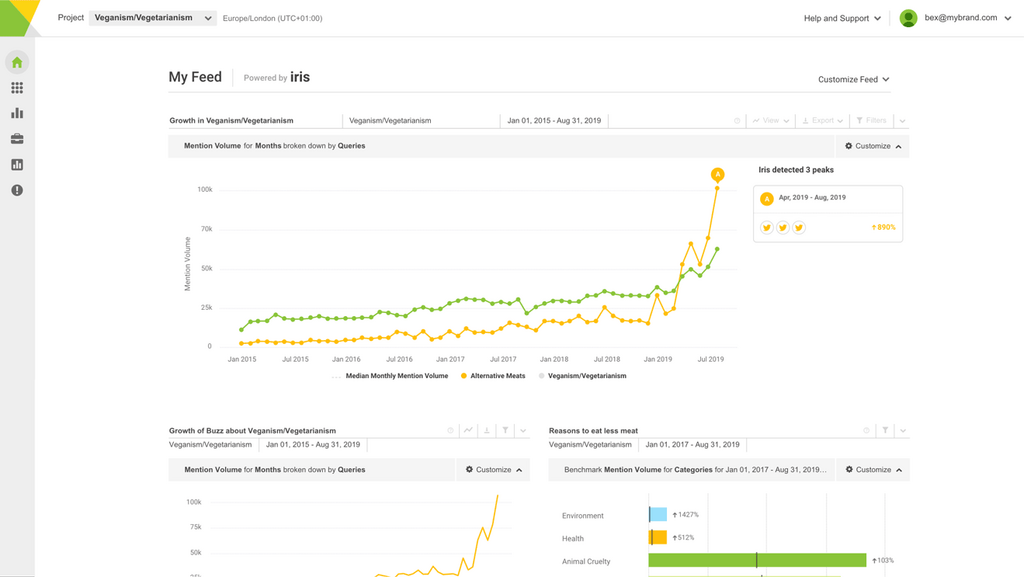
Im letzten Blogpost schrieb ich über unseren großen Fokus im ersten Quartal 2017: die Datenabdeckung in der Asien-Pazifik-Region.
Ich erwähnte in dem Post nicht unsere anderen Punkte, auf die wir vom Data Team uns dieses Jahr fokussieren: Verbesserungen an unseren hauseigenen Crawling-Technologien. Unser Daten-Crawling-Team kümmert sich um all unsere gecrawlten Quellen wie Facebook, Instagram, Blogs, Foren und News-Seiten.
In diesem Blogpost beantworte ich 7 Fragen, wie unsere Abdeckung von Instagram-Daten funktioniert.
1. Erhaltet ihr die Instagram Firehose?
Das ist eine häufig gestellte Frage.
Der Begriff „Firehose“ ist ein Branchenbegriff für eine bezahlte, volle Zufuhr von allen Daten einer bestimmten Quelle. Der bekannteste Anbieter einer Firehose ist Twitter. Wir bezahlen Twitter für die Daten und bekommen 100 Prozent aller Tweets für jede Kunden-Query. Wir haben ähnliche Übereinkommen mit Disqus und einer Zahl an anderen Anbietern.
Aber anders als bei Twitter gibt es keine Firehose für Instagram.
 Instagram ist Teil des Facebook-Konzerns, ein Werbeunternehmen. Gut, eigentlich positioniert sich Facebook als Medienunternehmen, aber es ist im Wesentlichen eine riesige, erfolgreiche Werbemaschine. Der Verkauf von Daten für Analytics-Zwecke passt nicht zu ihrem Geschäftsmodell. Facebook konzentriert sich darauf, eine gute Kundenerfahrung für seine Nutzer zu schaffen und die Werbungtreibenden dazu zu bringen, mehr Geld auszugeben. Mit dem Teilen von Daten unterstützt Facebook Werbungtreibende dabei, gezieltere und nützlichere Werbung für die Nutzer zu erstellen. Das Liefern von Verbraucher-Insights für Unternehmen ist nicht das Hauptaugenmerk und das ist der Grund, warum weder Facebook noch Instagram eine Firehose oder ein ähnliches Datenzahlungsmodell anbieten.
Instagram ist Teil des Facebook-Konzerns, ein Werbeunternehmen. Gut, eigentlich positioniert sich Facebook als Medienunternehmen, aber es ist im Wesentlichen eine riesige, erfolgreiche Werbemaschine. Der Verkauf von Daten für Analytics-Zwecke passt nicht zu ihrem Geschäftsmodell. Facebook konzentriert sich darauf, eine gute Kundenerfahrung für seine Nutzer zu schaffen und die Werbungtreibenden dazu zu bringen, mehr Geld auszugeben. Mit dem Teilen von Daten unterstützt Facebook Werbungtreibende dabei, gezieltere und nützlichere Werbung für die Nutzer zu erstellen. Das Liefern von Verbraucher-Insights für Unternehmen ist nicht das Hauptaugenmerk und das ist der Grund, warum weder Facebook noch Instagram eine Firehose oder ein ähnliches Datenzahlungsmodell anbieten.
Datenanbieter, die ihnen sagen, sie haben „100 Prozent aller Instagram-Daten“ oder die „Instagram Firehose“ sollten mit großer Skepsis behandelt werden.
2. Wie kommt ihr nun an Instagram-Daten?
Wir sitzen im gleichen Boot wie jeder andere: wir haben Zugriff auf die öffentlichen Instagram-APIs und crawlen diese Daten.
Einige Anbieter überspringen diesen Schritt und Bezahlen einen Aggregator, um für diese zu crawlen. Wir entschieden uns dagegen, das heißt wir haben die Kontrolle darüber, welche Daten wir sammeln (oft mehr als unsere Kunden fordern, aber mit weniger Spam und irrelevanten Erwähnungen). Da es öffentliche Daten sind und keine bezahlte API, haben wir wie alle Anbieter Ratenbegrenzungen. Daher müssen wir sehr genau darauf achten, wie wir die Dinge abwägen, die wir crawlen.
 Da es keine komplexe Such-API gibt (wie bei anderen Datenanbietern wie Twitter), können wir nicht die umfangreiche, Boolean Logik anwenden, die Sie normalerweise in einer Brandwatch Query anwenden würden.
Da es keine komplexe Such-API gibt (wie bei anderen Datenanbietern wie Twitter), können wir nicht die umfangreiche, Boolean Logik anwenden, die Sie normalerweise in einer Brandwatch Query anwenden würden.
Die API liefert eine Reihe an Endpunkten, um Instagram-Daten zu bekommen. Für die Nicht-Entwickler unter ihnen: Ein Endpunkt ist einfach ein Ort, von dem wir Daten von der API in einem bestimmten Format anfordern können. Gegenwärtig crawlen wir Posts für angeforderte Hashtags und Posts von spezifischen Nutzern. Vor kurzem haben wir die Kommentarsuche für Nutzer-Posts eingeführt.
3. Wie funktioniert das Crawlen von Instagram Hashtag Posts?
Konzeptionell kann das in zwei Aktivitäten aufgeteilt werden. Als erstes die Posts von Instagram zu bekommen und als zweites, es Ihren Queries zuzuordnen.
Posts von Instagram erhalten: Da es keine komplexe Such-API gibt, durchsuchen wir Instagram Tags-Endpunkte.
Dadurch erhalten wir eine Liste an Posts für ein bestimmtes Hashtag. Wir sammeln eine Liste aller Hashtags, die in unseren Kunden-Queries erwähnt wurden (indem Nutzer mithilfe des hashtag:-Operatoren suchten). Die Liste wird dann durchgearbeitet und wir fordern die Posts für jedes Hashtag an.
Die Aufforderung gibt eine Seite mit mehreren Posts zurück, das wiederholen wir und erhalten so mehrere Seiten mit Posts. Jeder Posts wird dann aufbewahrt und stehen Kunden-Queries zur Verfügung, die nach diesen Posts suchen.
Den Kunden-Queries zuordnen: Sobald sich ein Post im Brandwatch Datenarchiv befindet, können sie jeder Kunden-Query zugeordnet werden, egal ob es sich auf das Hashtag, das sich im Post befindet, bezieht.
Beispielsweise, wenn ein Kunde eine Query für hashtag:cats erstellt und wir finden einen Instagram Post, der folgenden Text enthält „I’m so glad I don’t have a dog. #cats“, dann ordnen wir diesen Post der Query zu. Wir ordnen diesen Post aber auch einer Suchanfrage zu, die nach jeder Erwähnung zum Word „dog“ sucht (auch, wenn nach keinem Hashtag gesucht wird).
Wir nennen das „einhergehende Daten“ – es ist eine Art Netzwerkeffekt, wenn die Daten, die wir von einem Kunden abfragen, einen Nutzen für alle unsere Kunden liefern kann.
Nur um das Klarzustellen: Ich bin eigentlich keine Katzenliebhaberin.

4. Wie funktioniert das Crawlen von Instagram User-Posts und -Kommentaren
Diese Möglichkeit gibt es in unserer Brandwatch Analytics Channels-Feature für Instagram.
Die Anwendung ist sehr einfach im Vergleich zum Aufsetzen einer regulären Query. Dafür setzen Sie einfach einen Channel auf und geben an, welchen Instagram-Nutzer Sie hinzufügen möchten. Daraufhin fangen wir an, die Posts des Nutzer zu durchsuchen, sowie die dazugehörigen Kommentare oder Likes.
Wenn Sie einen Channel aufsetzen, erhalten wir nach dem ersten Crawl die letzten 100 Posts, die in den letzten sieben Tagen veröffentlicht wurden. Für jeden Post erhalten wir bis zu 150 Kommentare. Danach besuchen wir die Nutzerseite alle ein bis zwei Stunden (das hängt davon ab, wie lange der letzt Crawling-Zyklus gedauert hat und die Hardware, die dafür verwendet wurde) und erhalten dadurch die Top 100 Posts und bis zu 150 Kommentare je Post.
5. Warum bittet mich Brandwatch darum, mich mit Instagram zu authentifizieren?
Sie haben vielleicht die Nachricht in Brandwatch gesehen, die danach fragt, dass Sie sich mit Instagram authentifizieren oder Ihnen ist das Authentifizierungsmenü in der oberen rechten Ecke der App aufgefallen:
 Jedes Mal, wenn wir uns mit der API verbinden, müssen wir ein „Token“ präsentieren. Ein Token ist im Grunde einfach ein Ticket, um Zutritt zu erhalten.
Jedes Mal, wenn wir uns mit der API verbinden, müssen wir ein „Token“ präsentieren. Ein Token ist im Grunde einfach ein Ticket, um Zutritt zu erhalten.
Die Herausforderung besteht darin, dass diese Tokens nur begrenzt oft genutzt werden können und müssen nach einem Zeitraum erneuert werden. Umso mehr Tokens wir haben, umso mehr Crawling-Kapazitäten haben wir. Jeder Instagramnutzer-Account kann ein Token erzeugen, welches wir speichern und nutzen können, um die Crawling-Kapazitäten zu erhöhen.
An verschiedenen Stellen in Brandwatch bieten wir ein hohes Service-Level für Personen an, die sich in der Plattform authentifiziert haben und dadurch ein Token erstellten. Das sind gegenwärtig zwei Bereiche:
- Crawling von Hashtags – Wir verfügen über eine zweite Möglichkeit des Hashtag-Crawlings, den „Authenticated Hashtag Crawler“, der Kapazitäten für Hashtags liefert, die von Klienten gesucht werden, die einen oder mehrere Instagram-Accounts authentifiziert haben.
- Crawling von User-Posts und Kommentaren – Dieser Crawler befindet sich im Brandwatch Analytics Channels Feature. Jedes authentifizierte Token kann bis zu 50 Channels bearbeiten (oder in Instagramsprache: kann Analysen für bis zu 50 Instagram Accounts liefern). Für einige Channels, die ein hohes Volumen liefern (die viele Posts und Kommentare enthalten), kann es zu Abdeckungsproblemen kommen, wenn unser Nutzer ein geringes Level an Tokens liefern. Die Authentifizierung kann in diesen Fällen also helfen.
6. Was kann ich tun, um mehr Instagram-Daten zu erhalten?
Wir haben einige Vorschläge, um das Beste aus unseren Datenabfrageprozessen zu holen.
- Optimieren Sie Ihre Brandwatch Analytics Queries, indem Sie Instagram Hashtags hinzufügen, die wir für Sie abfragen sollen.
- Erstellen Sie einen Brandwatch Analytics Instagram Channel für die Accounts, die wir verfolgen sollten (wie zum Beispiel Ihre markeneigene Instagram-Seite).
- Authentifizieren Sie Ihre Instagram Accounts mit Brandwatch Analytics. Das stellt sicher, dass Sie ein bisschen extra Crawling-Kapazität erhalten; das wirkt sich vor allem für Brandwatch Analytics Channels mit hohem Volumen positiv aus.
- Wenn Sie Influencer haben, die sehr wichtig für Sie sind, erstellen Sie Instagram Channels von ihren Accounts und diese Daten stehen dann all Ihren anderen Queries zur Verfügung.
7. Was steht auf der Roadmap für das Instagram Crawling?
 Wir wollen mehr und uns in naher Zukunft in diesen drei Bereichen verbessern:
Wir wollen mehr und uns in naher Zukunft in diesen drei Bereichen verbessern:
1. Tiefgang der Hashtag-Abdeckung – Sicherzustellen, dass wir jeden letzten Post für alle von Nutzern angefragten Hashtags erhalten, auch denen mit sehr hohem Volumen.
2. Breite der Hashtag-Abdeckung – Mehr Crawling von nicht-angefragten Hashtags, so dass wir mit der Zeit über bessere historische Daten verfügen. Eine interessante Richtung könnte sein, andere Hashtags, die wir bei eingehenden Posts von unseren Crawlern sehen, hinzuzufügen.
3. Kommentare für die Hashtag-Abdeckung – Es liegt ein großer Nutzen darin, die Antworten und Gespräche rund um relevante Posts einzufangen – unter Umständen nicht nur jene im Ursprungspost.
Im Moment ist der erste Punkt unsere Priorität. Wir haben ein neues Technikteam zusammengestellt, welches sich darum kümmert und sie machen rasche Fortschritte bei einigen großen architektonischen Verbesserungen. Dadurch erhöht sich die Anzahl an Posts, die wir erhalten radikal.
CTA